26号的第二篇,问就是懒瘾犯了……🥺,大概知道了PE文件的结构后,其实就可以进行加壳的尝试了。
整个加壳过程需要的东西有:源程序、壳程序、加壳器。
这里提一嘴我在加壳中用到的工具与环境:
- VS2022(配置了OLLVM17.0.6,用于代码混淆)
- PyCharm(配置了第三方lief库,用于加壳器的编写。关于lief的使用方法,可以看这篇文章1)
先说一下我的加壳思路:我是将源程序加密后存储到壳程序的一个新建节区中,节区名字可以自定义(默认是.pack),当然也可以将源程序分段存储,我为了实现方便就用最简单的方式。
1. 壳程序
壳程序的功能包括:
-
源程序所在节区的节区名查寻(因为是自定义节区名,默认节区名是.pack);
-
源程序的解密(我在加壳器里写了简单的异或加密,如果有需求可以自行更改);
-
源程序的加载(将源程序加载到内存中);
-
源程序的IAT表以及重定位表的修改(为了使源程序能够正确加载到想要的函数);
-
TLS反调试以及简单花指令(增加调试难度,后续可以再更改)
1.1 源程序加载
先给出加载函数的代码:(我这里借用了吾爱的一位佬2的代码)
void* load_PE(char* PE_data) {
IMAGE_DOS_HEADER* p_DOS_header = (IMAGE_DOS_HEADER*)PE_data;
IMAGE_NT_HEADERS* p_NT_headers = (IMAGE_NT_HEADERS*)(PE_data + p_DOS_header->e_lfanew);
DWORD size_of_image = p_NT_headers->OptionalHeader.SizeOfImage;
DWORD entry_point_RVA = p_NT_headers->OptionalHeader.AddressOfEntryPoint;
DWORD size_of_headers = p_NT_headers->OptionalHeader.SizeOfHeaders;
char* p_image_base = (char*)VirtualAlloc(NULL, size_of_image, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
if (p_image_base == NULL) {
return NULL;
}
mymemcpy(p_image_base, PE_data, size_of_headers);
IMAGE_SECTION_HEADER* sections = (IMAGE_SECTION_HEADER*)(p_NT_headers + 1);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {
char* dest = p_image_base + sections[i].VirtualAddress;
if (sections[i].SizeOfRawData > 0) {
mymemcpy(dest, PE_data + sections[i].PointerToRawData, sections[i].SizeOfRawData);
}
else {
for (size_t i = 0; i < sections[i].Misc.VirtualSize; i++) {
dest[i] = 0;
}
}
}
fix_iat(p_image_base, p_NT_headers);
fix_base_reloc(p_image_base, p_NT_headers);
DWORD oldProtect;
VirtualProtect(p_image_base, p_NT_headers->OptionalHeader.SizeOfHeaders, PAGE_READONLY, &oldProtect);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; ++i) {
char* dest = p_image_base + sections[i].VirtualAddress;
DWORD s_perm = sections[i].Characteristics;
DWORD v_perm = 0;
if (s_perm & IMAGE_SCN_MEM_EXECUTE) {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_EXECUTE_READWRITE : PAGE_EXECUTE_READ;
}
else {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_READWRITE : PAGE_READONLY;
}
VirtualProtect(dest, sections[i].Misc.VirtualSize, v_perm, &oldProtect);
}
return (void*)(p_image_base + entry_point_RVA);
}
值得注意的是,IAT表与重定位表的修复需要在节区加载进入内存之后进行,因为只有当节区中的内容加载内存中,函数信息也才会被加载进入内存中,然后才能根据相应的地址对函数地址表以及重定位表进行修改。
1.2 导入函数地址表(IAT)与重定位表的修改
导入函数地址表修复函数:
//IAT表的修复
void fix_iat(char* p_image_base, IMAGE_NT_HEADERS* p_NT_headers) {
IMAGE_DATA_DIRECTORY* data_directory = p_NT_headers->OptionalHeader.DataDirectory;
IMAGE_IMPORT_DESCRIPTOR* import_descriptors =
(IMAGE_IMPORT_DESCRIPTOR*)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
for (int i = 0; import_descriptors[i].OriginalFirstThunk != 0; ++i) {
char* module_name = p_image_base + import_descriptors[i].Name;
HMODULE import_module = LoadLibraryA(module_name);
if (import_module == NULL) {
ExitProcess(255);
}
IMAGE_THUNK_DATA* lookup_table = (IMAGE_THUNK_DATA*)(p_image_base + import_descriptors[i].OriginalFirstThunk);
IMAGE_THUNK_DATA* address_table = (IMAGE_THUNK_DATA*)(p_image_base + import_descriptors[i].FirstThunk);
for (int i = 0; lookup_table[i].u1.AddressOfData != 0; ++i) {
void* function_handle = NULL;
DWORD lookup_addr = lookup_table[i].u1.AddressOfData;
if ((lookup_addr & IMAGE_ORDINAL_FLAG) == 0) {
IMAGE_IMPORT_BY_NAME* image_import = (IMAGE_IMPORT_BY_NAME*)(p_image_base + lookup_addr);
char* funct_name = (char*)&(image_import->Name);
function_handle = (void*)GetProcAddress(import_module, funct_name);
}
else {
function_handle = (void*)GetProcAddress(import_module, (LPSTR)lookup_addr);
}
if (function_handle == NULL) {
ExitProcess(255);
}
address_table[i].u1.Function = (DWORD)function_handle;
}
}
}
这里说一下为什么在修复IAT之后还要修复重定位表?重定位表需要重定位是为了解决加载地址与编译时首选地址不一致的问题,确保程序在内存中的地址引用始终有效。
重定位表修复函数:
//重定位表的修复
void fix_base_reloc(char* p_image_base, IMAGE_NT_HEADERS* p_NT_headers) {
IMAGE_DATA_DIRECTORY* data_directory = p_NT_headers->OptionalHeader.DataDirectory;
DWORD delta_VA_reloc = ((DWORD)p_image_base) - p_NT_headers->OptionalHeader.ImageBase;
if (data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress != 0 && delta_VA_reloc != 0) {
IMAGE_BASE_RELOCATION* p_reloc =
(IMAGE_BASE_RELOCATION*)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
while (p_reloc->VirtualAddress != 0) {
DWORD size = (p_reloc->SizeOfBlock - sizeof(IMAGE_BASE_RELOCATION)) / 2;
WORD* fixups = (WORD*)(p_reloc + 1);
for (size_t i = 0; i < size; ++i) {
int type = fixups[i] >> 12;
int offset = fixups[i] & 0x0fff;
DWORD* change_addr = (DWORD*)(p_image_base + p_reloc->VirtualAddress + offset);
switch (type) {//由于壳程序的一些字段类型用的32位的,所以为了统一,这里只做32位源程序的判断(后续再对整体完善补充)
case IMAGE_REL_BASED_HIGHLOW:
*change_addr += delta_VA_reloc;
break;
default:
break;
}
}
p_reloc = (IMAGE_BASE_RELOCATION*)(((DWORD)p_reloc) + p_reloc->SizeOfBlock);
}
}
}
1.3 TLS回调反调试
TLS回调反调试的原理很简单,就是利用TLS函数会在线程创建与结束时被调用的特性,来对整个程序进行反调试检测。详细的可以参考这篇文章3。
TLS回调函数:(我这里虽然写了x64与x86两种架构的判断,但实际上只用到了x86的判断)
// 创建TLS段
EXTERN_C
#ifdef _M_X64
#pragma const_seg (".CRT$XLB")
PIMAGE_TLS_CALLBACK _tls_callback = TLS_CALLBACK;
#else
#pragma data_seg (".CRT$XLB")
PIMAGE_TLS_CALLBACK _tls_callback = TLS_CALLBACK;
#endif
// linker spec 通知链接器PE文件要创建TLS目录
#ifdef _M_IX86
#pragma comment (linker, "/INCLUDE:__tls_used")
#pragma comment (linker, "/INCLUDE:__tls_callback")
#else
#pragma comment (linker, "/INCLUDE:_tls_used")
#pragma comment (linker, "/INCLUDE:_tls_callback")
#endif
void NTAPI __stdcall TLS_CALLBACK(PVOID DllHandle, DWORD Reason, PVOID Reserved)
{//它会根据Reason时机进行调试判断
if (IsDebuggerPresent())
{
MessageBoxW(NULL, L" TLS_CALLBACK: do not debug !", L"TLS Callback", MB_ICONSTOP);
ExitProcess(0);
}
}
1.4 壳程序主函数
主函数的逻辑里就包括了异或解密与源程序加载,而三段简单的花指令被我围绕加在了加载函数的附近。
其实关于源程序加载有人可能感到迷惑。如果只是加载源程序,那么为什么不直接修改壳程序的入口地址呢?因为这样会影响壳解密(如果有的话),想想,如果入口地址直接被改成源程序的起始地址,那么壳程序中写的逻辑又该怎么执行呢?所以还是得自行实现PE加载。
异或解密函数如下:
void decrypt_PE_data(char* data, size_t length, unsigned char key) {//一个字节一个字节处理
for (size_t i = 0; i < length; i++)
{
data[i] ^= key;
}
}
主函数如下:
int main() {
char* unpacker_VA = (char*)GetModuleHandleA(NULL); //这里获取的是壳程序的起始地址
IMAGE_DOS_HEADER* p_DOS_header = (IMAGE_DOS_HEADER*)unpacker_VA; //DOS头
IMAGE_NT_HEADERS* p_NT_headers = (IMAGE_NT_HEADERS*)(((char*)unpacker_VA) + p_DOS_header->e_lfanew); //NT头
IMAGE_SECTION_HEADER* sections = (IMAGE_SECTION_HEADER*)(p_NT_headers + 1); //节区头
char* packed = NULL;
char packed_section_name[7] = { 0 };//节区名
//到内存中对节区名寻址(我在加壳节区名字写到data节区的尾部)
char* data_address = NULL;
char data_section_name[] = ".data";
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {//这里是为了找到新添加节区的节区名字
if (mystrcmp(sections[i].Name, data_section_name) == 0)
{
data_address = unpacker_VA + sections[i].VirtualAddress;
break;
}
}
//找到后再利用偏移找到相应的数据值(6字节数据)
char section_name[7] = { 0 }; //多分配一个字节避免字符串末尾无结束符
size_t offset = 0x1f0;
//将数据读取出来(共6字节数据)
mymemcpy(section_name, data_address + offset, 6);
//然后再传递节区名
mymemcpy(packed_section_name, section_name, 6);
//这里是为了找到新添加节区的地址(因为新节区是源程序起始地址)
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {
if (mystrcmp(sections[i].Name, packed_section_name) == 0) {
packed = unpacker_VA + sections[i].VirtualAddress;
break;
}
}
if (packed != NULL) {
//找到后就先进行解密处理
unsigned char key = 36; //异或密钥,后面可以再改
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++)
{
if (mystrcmp(sections[i].Name, packed_section_name) == 0) {
//先找到对应节区在文件中的大小,即:加密长度
size_t encrypted_length = sections[i].SizeOfRawData;
//解密源程序(节区起始地址、加密长度、密钥)
decrypt_PE_data(packed, encrypted_length, key);
}
}
//花指令1
#ifdef _MSC_VER
// Visual Studio 风格
__asm {
mov eax, 0
test eax, eax
jne label1
label1 :
}
#else
// GCC/Clang 风格
__asm__ volatile (
"movl $0, %%eax\n\t"
"test %%eax, %%eax\n\t"
"jne label\n\t"
"label:\n\t"
:
:
: "%eax"
);
#endif
//花指令2
#ifdef _MSC_VER
// Visual Studio (MASM 风格汇编)
__asm {
call _next;
_next:
mov dword ptr[esp], offset _label2
ret
_label2 :
}
#else
// GCC/Clang (GNU 风格汇编)
__asm__ volatile (
"call 1f;\n" // 调用 next
"1:\n" // 局部标签 next
"movl $2f, (%esp);\n" // 修改返回地址为 offset_label2
"ret;\n" // 返回到 offset_label2
"2:\n" // 局部标签 offset_label2
:
:
: "memory"
);
#endif
//将源程序加载进内存中
void (*entrypoint)(void) = (void (*)(void))load_PE(packed);
//花指令3
int data = 0x1234;//junk变量
#ifdef _MSC_VER
// Visual Studio 下的 MASM 风格汇编
__asm {
mov eax, data;
xor eax, 0x5678;
mov data, eax;
}
#else
// GCC/Clang 下的内联汇编
__asm__ volatile (
"movl %0, %%eax\n\t"
"xorl $0x5678, %%eax\n\t"
"movl %%eax, %0\n\t"
: "+r" (data)
:
: "%eax"
);
#endif
//运行源程序
entrypoint();
}
return 0;
}
主函数没什么好说的,关于那三段花指令,实际上只有第二段才不会被IDA的反汇编直接识别,它的逻辑我在代码段中已经说明了,作用就是干扰像IDA一类的反汇编,使之出现栈分析出错的效果。
下面看一下加花指令前后的对比图:
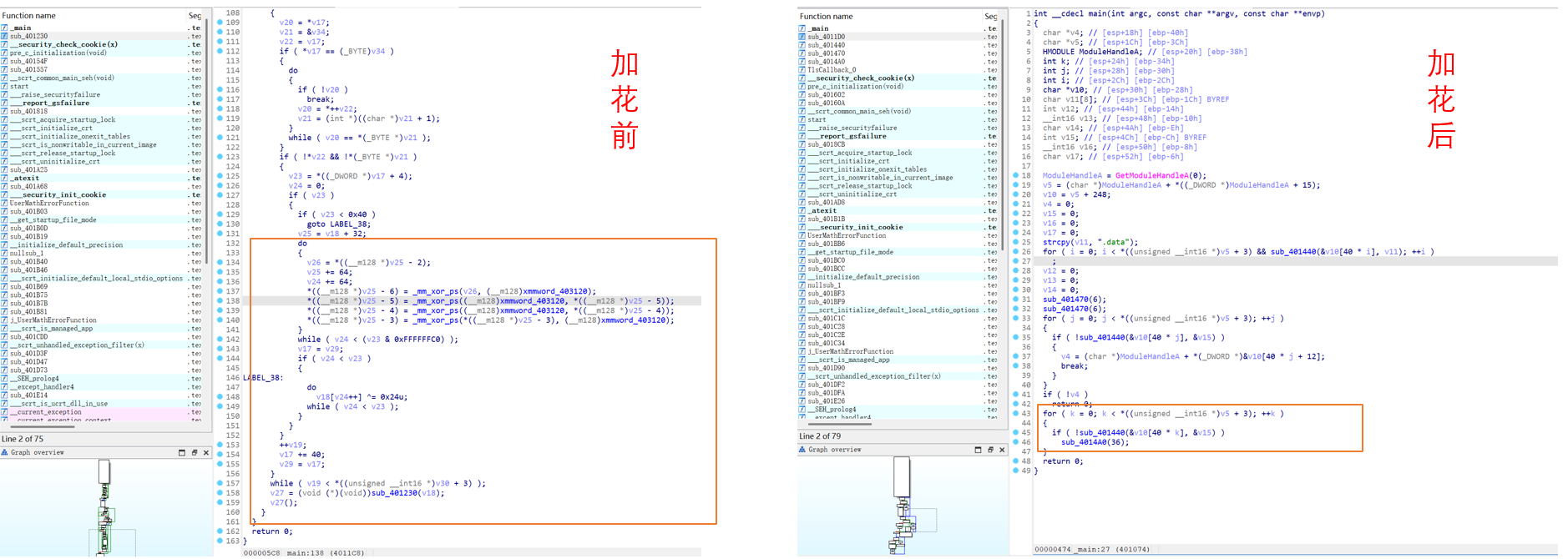
1.5 OLLVM混淆
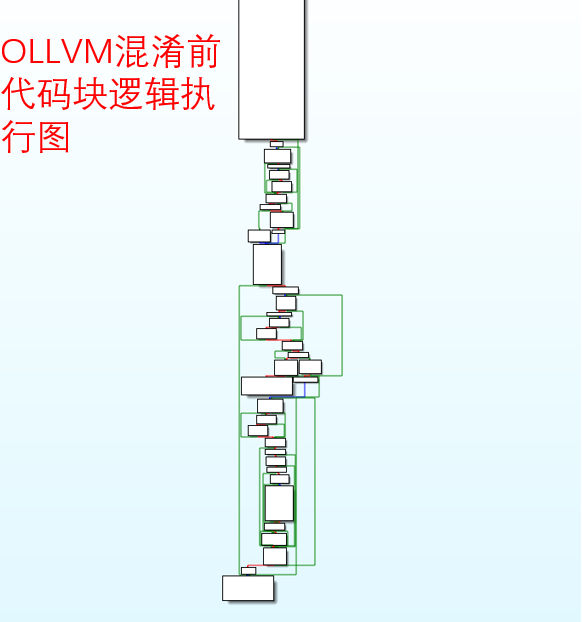
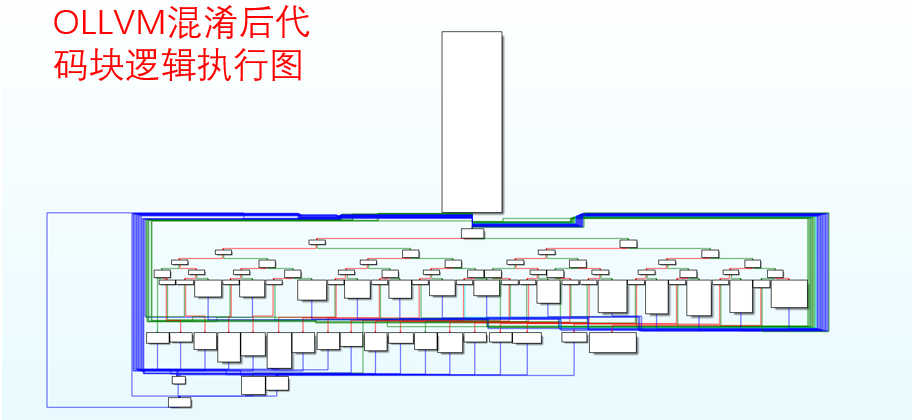
OLLVM项目自带Clang编译器,被我配置在了项目里。我这里OLLVM的配置方式很简单(相较于自己编译OLLVM项目而言),参考的是这篇帖子4。
关于OLLVM的介绍、它在Linux上的配置以及在Linux上的使用方法可以去看我的另几篇帖子。
下面给看一下使用OLLVM混淆前后的对比。
混淆前:
混淆后:
2. 加壳器
加壳器我这里用的python写的,主要是为了方便使用这个lief,这个库里的一些API函数可以自动完成对PE头的修改、节区头的创建以及字段的自动填充。
加壳器代码如下:
import lief
from modules.m2.utils import *
# 将源程序以节区形式添加到壳中,并重新构建壳程序
def main():
# 解析壳PE文件以作他用
pe = lief.PE.parse(r"") # 这里添加自己的壳文件存储路径
if pe is None:
raise RuntimeError("Failed to parse the PE")
# 读取源程序内容(转为了字节数组)
program = read_file(r"") # 这里添加自己想要加壳的文件存储路径
## 对源程序进行加密处理
key = 36 # 这里对密钥进行硬编码
encrypted_program = xor_encrypt(program,key)
# 加密后进行节区对齐(由于我这里是进行的异或加密,所以节区对齐前后无变化,如果之后有其他加密,肯定要进行节区对齐)
file_alignment = pe.optional_header.file_alignment
aligned_data = align_data(encrypted_program,file_alignment)
## 可以在这里添加节区名选择(不管自定义还是选择就很麻烦,都需要定位修改二进制数据)
# 先将节区名字填入到.data节区中
section_name = input("Input section name (Max size is 6bytes, like\".packed\"):")
# 做一个判断校验
if len(section_name.encode('utf-8')) > 6 or not section_name:
section_name = ".pack" # 默认节区名
# 将数据转为字节形式
section_name_bytes = bytes(section_name, encoding="utf-8")
# 找到.data节区
data_section = next((s for s in pe.sections if s.name == ".data"), None)
if data_section is None:
raise RuntimeError("Failed to find the .text section.")
# 记录字符串相对节区偏移
data_section_add_offset = 0x1f0 # 这里我随便找的一处空位
# 将数据填入到.data节区的偏移地址中
data_section_content = list(data_section.content) # 获取当前节区的内容数据
data_section_content[data_section_add_offset:data_section_add_offset+len(section_name_bytes)] = list(section_name_bytes) # 从偏移处开始覆盖数据
data_section.content = list(data_section_content) # 将修改数据写回节区中
# 创建新的节区(自定义节区名)
packed_section = lief.PE.Section(section_name) # 也可以默认.packed
# 将加密后的源程序注入到节区内容中
packed_section.content = list(aligned_data)
# 设置节区特征值(没找到,看硬编码能不能行)
packed_section.characteristics = (
0x40000000 | # MEM_READ
0x80000000 | # MEM_WRITE
0x00000040 # CNT_INITIALIZED_DATA
)
# 将设置好的节区添加到壳中
pe.add_section(packed_section, lief.PE.SECTION_TYPES.DATA)
# 添加完成后重新对壳PE进行构建
builder = lief.PE.Builder(pe)
builder.build()
builder.write("packed32.exe") # 这里也可以自己改成喜欢的名字
print("Packed is over")
if __name__ == '__main__':
try:
main()
except Exception as e:
print(f"Error: {e}")
关于自定义节区名,我这里采用的是比较简单粗暴的方式:壳程序写好后,我用PEview查看每个节区有没有空余的空间,结果发现.data节区有,所以我直接将.data节区末16字节的首字节的位置偏移值以硬编码的方式写到了代码里,如下:
# 记录字符串相对节区偏移
data_section_add_offset = 0x1f0
目的就是为了将自定义的节区名字存到这里,然后使壳程序加载时能够找到源程序所在节区的位置。
这种行为有点蠢,不值得提倡,后续需要更改。
加壳器的工具类代码如下:
import os
## 返回对齐后的大小(支持文件对齐/内存对齐)
# parm1:节区数据
# parm2:节区对齐单位
def align(data, alignment):
return (len(data) + alignment - 1) & ~(alignment - 1)
## 将节区数据进行对齐填充(支持文件对齐)
# parm1:加密后的数据
# parm2:节区对齐单位
def align_data(data, alignment):
padding = (alignment - (len(data) % alignment)) % alignment
return data + b'\x00' * padding
# 异或加密(后续如果有需要可以在此基础上修改)
def xor_encrypt(data, key):
return bytearray(b ^ key for b in data)
# 读取文件并返回二进制形式
def read_file(path):
# 先判断文件是否存在
if not os.path.exists(path):
raise FileNotFoundError(f"File is not found:{path}")
with open(path,"rb") as f:
return f.read()
由于我这里采用的是简单的异或加密,因此节区对不对齐影响不大,如果用其他加密方式还是要考虑对齐。
文章写的比较粗糙,后面会再慢慢修改,请多见谅😟