今年网鼎青龙组初赛的逆向题质量有点一般,而且只有两道。下面给出两道题的解析与复现。
REVERSE01
这道题虽然是安卓题,但涉及到安卓相关的东西很少,而且只要静态分析就能解出,有点难绷……
首先拿到APK去检测一下有没有加壳,发现没有壳,如下图:
JAVA层分析
无壳,直接拖进jadx查看源码,如下图:
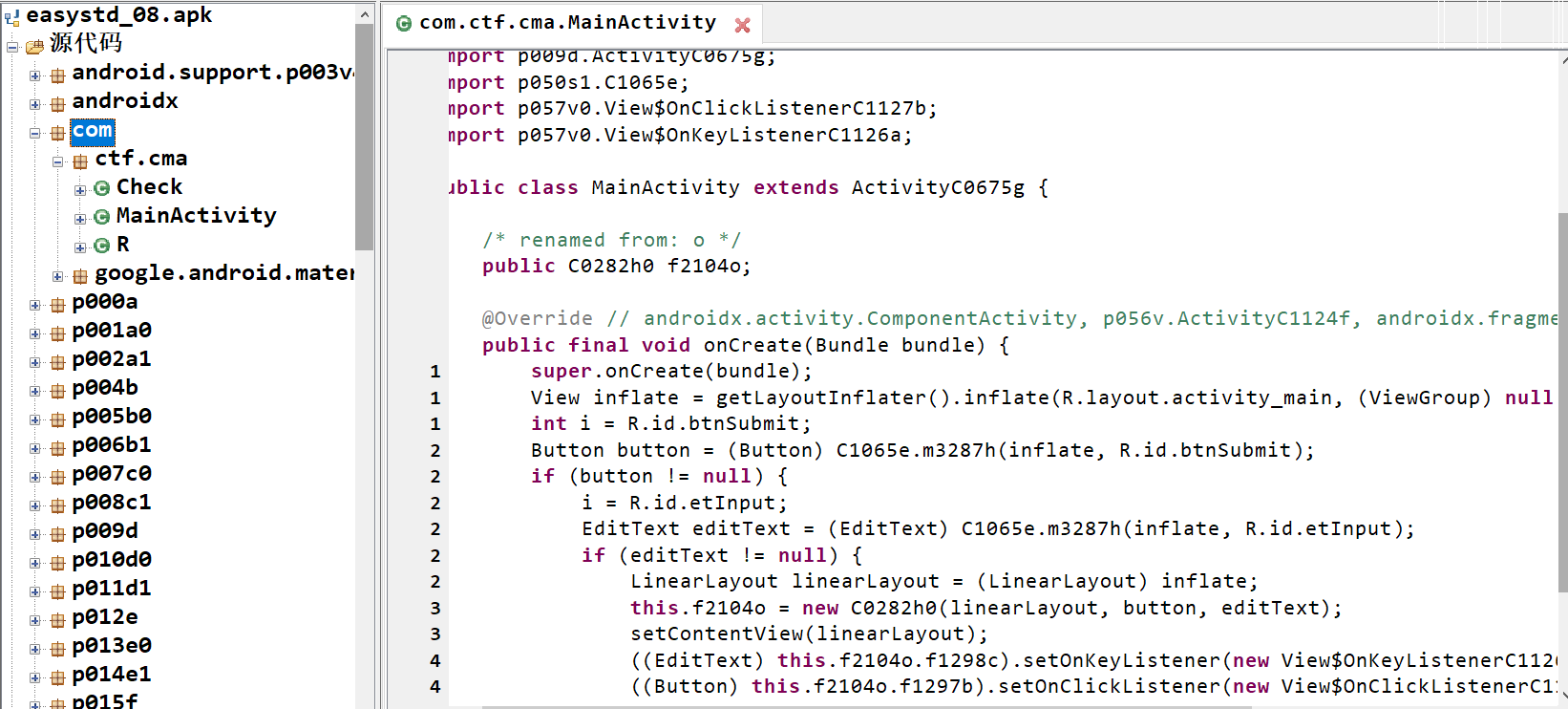
好好好,发现被混淆了,其实被混淆了也不用着急,因为一些方法还是能看出来,分析了一下,这里的Main活动没有输入判断的逻辑。然后将APK放进模拟器运行一下,看有没有啥关键词(其实混淆后字符串之类的关键词大概率是搜不到的),发现输入错误后会有Toast提示,所以可以去搜索Toast关键词来找到输入判断的地方。
果然,用Toast当关键词搜索有用,如下图:
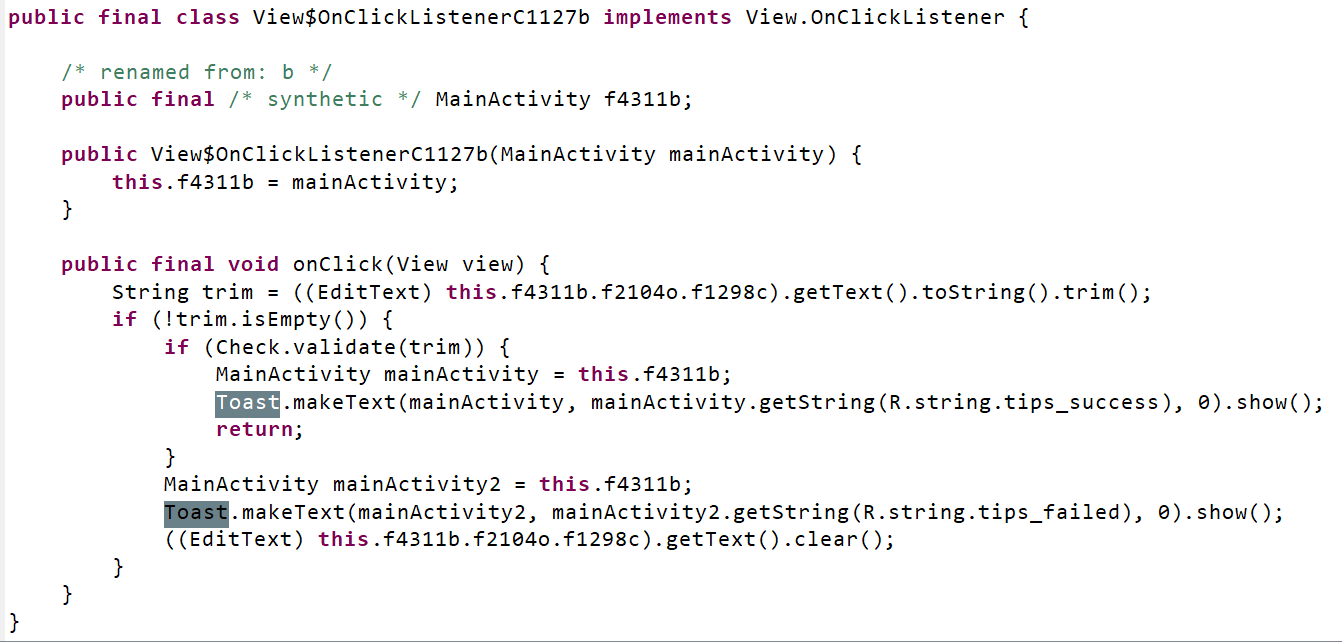
发现我们的输入先进行了一个是否为空的判断后,再进入了一个Check类的validate方法中去进行最终判断,如果正确就提示正确信息,否则就提示输入错误。
而Check类下的validate是一个native方法,所以解题关键是在so文件中逆向该方法。
Native函数分析
libcma.so文件拿去ida分析后,发现这个函数名也被混淆了,就是被拿去JNI_OnLoad函数中动态注册了,进注册表中看注册的函数名,发现validate被映射到了一个叫做sub_75C的函数,如下图:
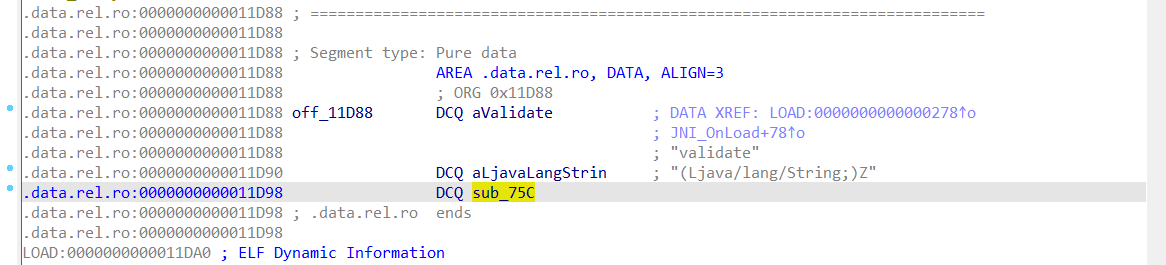
所以进入sub_75C函数去查看逻辑,如下图:
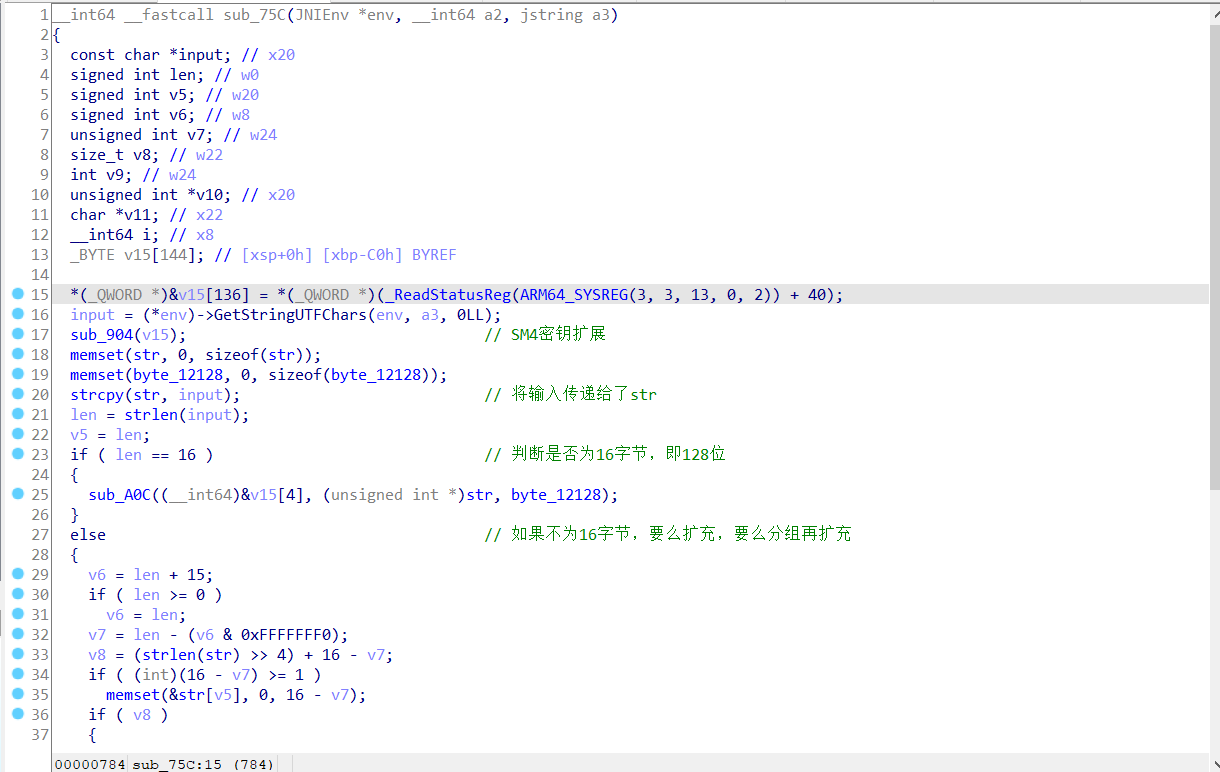
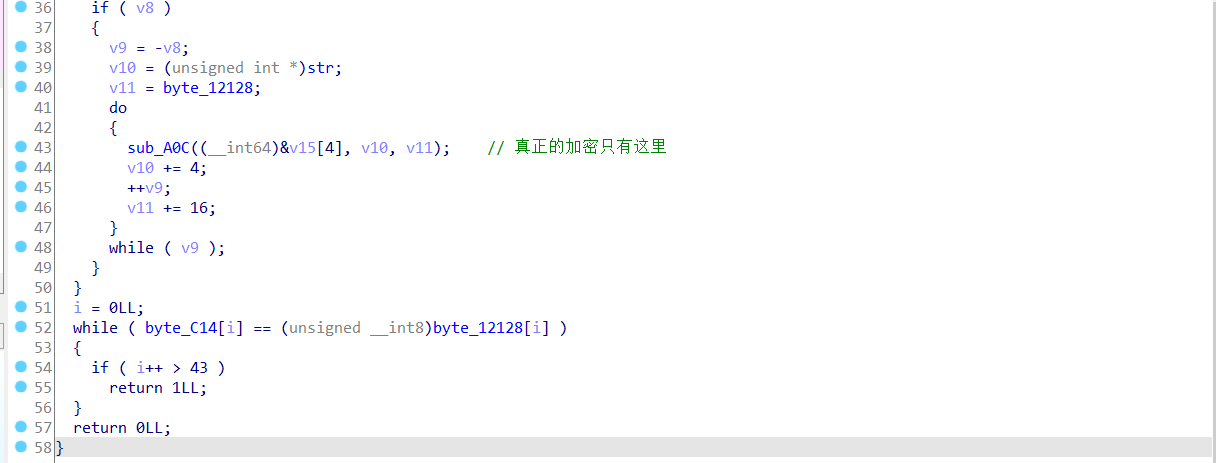
先给出结论,整个sub_75C函数包括了SM4密钥扩展和SM4加密,下面给出分析。
SM4密钥扩展
先来看下密钥扩展部分的代码也就是sub_904函数,如下图:
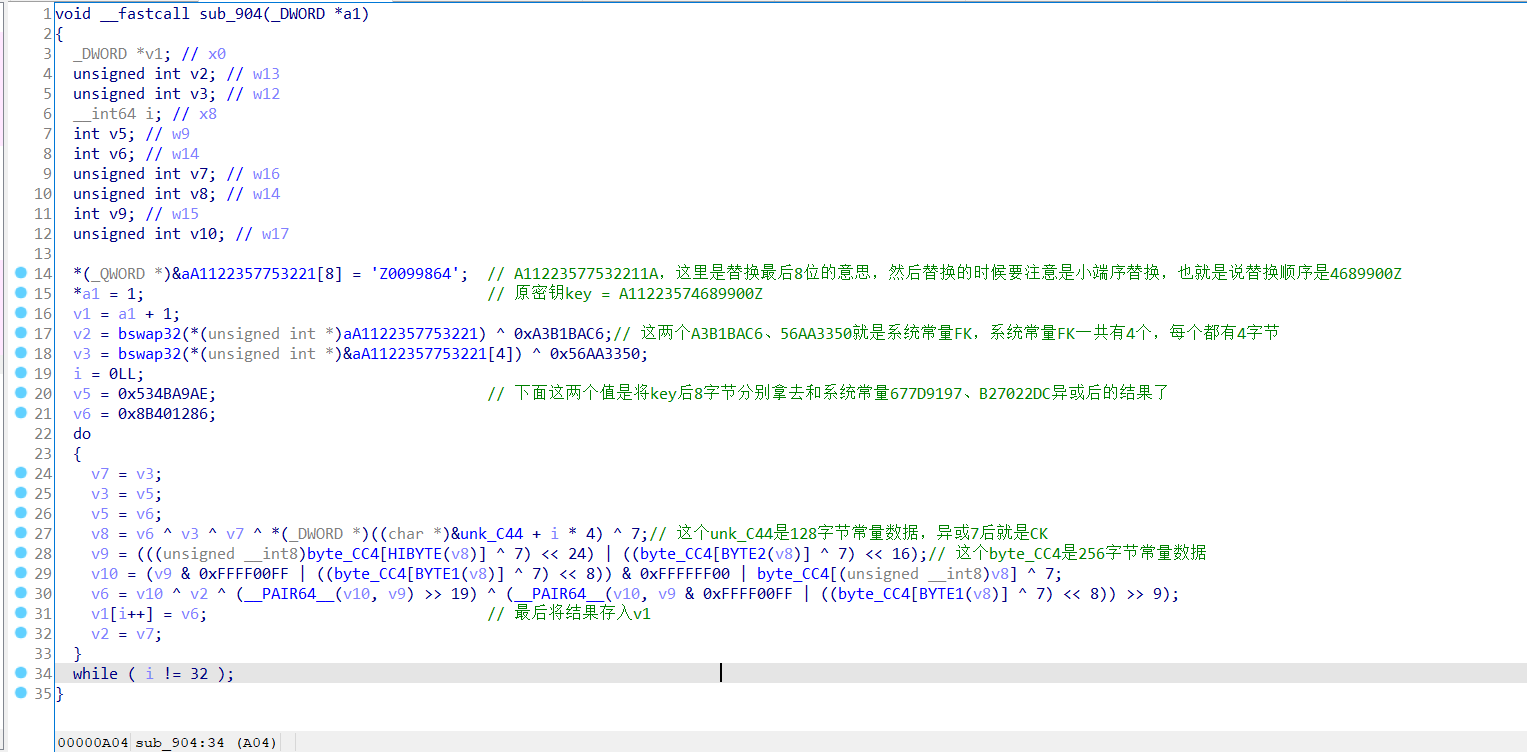
为什么看出来这个算法是SM4,而不是其它什么算法,就是因为在SM4的密钥扩展中有两个不变的参数,一个是系统参数FK,另一个是固定参数CK。从这里就可以基本判断出这是一个SM4加密算法。
其中FK共有4个,每个都有4字节长,它们的值如下:
FK = [0xa3b1bac6, 0x56aa3350, 0x677d9197, 0xb27022dc]
而CK共有32个,每个同样有4字节长,它们的值如下:
CK = [
0x00070e15, 0x1c232a31, 0x383f464d, 0x545b6269,
0x70777e85, 0x8c939aa1, 0xa8afb6bd, 0xc4cbd2d9,
0xe0e7eef5, 0xfc030a11, 0x181f262d, 0x343b4249,
0x50575e65, 0x6c737a81, 0x888f969d, 0xa4abb2b9,
0xc0c7ced5, 0xdce3eaf1, 0xf8ff060d, 0x141b2229,
0x30373e45, 0x4c535a61, 0x686f767d, 0x848b9299,
0xa0a7aeb5, 0xbcc3cad1, 0xd8dfe6ed, 0xf4fb0209,
0x10171e25, 0x2c333a41, 0x484f565d, 0x646b7279
]
关于CK的值,这里要提一句,ida反编译出来的伪C出来的CK‘值如下:
unsigned int unk_C44[32] = {
0x00070E12, 0x1C232A36, 0x383F464A, 0x545B626E,
0x70777E82, 0x8C939AA6, 0xA8AFB6BA, 0xC4CBD2DE,
0xE0E7EEF2, 0xFC030A16, 0x181F262A, 0x343B424E,
0x50575E62, 0x6C737A86, 0x888F969A, 0xA4ABB2BE,
0xC0C7CED2, 0xDCE3EAF6, 0xF8FF060A, 0x141B222E,
0x30373E42, 0x4C535A66, 0x686F767A, 0x848B929E,
0xA0A7AEB2, 0xBCC3CAD6, 0xD8DFE6EA, 0xF4FB020E,
0x10171E22, 0x2C333A46, 0x484F565A, 0x646B727E
};
很明显CK’不是CK,但是要注意,ida中是将CK‘异或了7,异或了7之后就会发现,变成了原CK的值。类似的异或在后面的SM4加密环节中还会再出现一次。
因此判断出了这是SM4的密钥扩展之后,只需要找到原密钥即可。而原密钥在该函数的开头就已经给出,这里只需要注意替换后8字节数据时,ida是小端序输入,所以需要将Z0099864倒叙替换。
所以原密钥key = 4131313232333537343638393930305A(我这里已经写成了十六进制形式)
SM4轮函数
继续分析主加密函数sub_A0C,如下图:
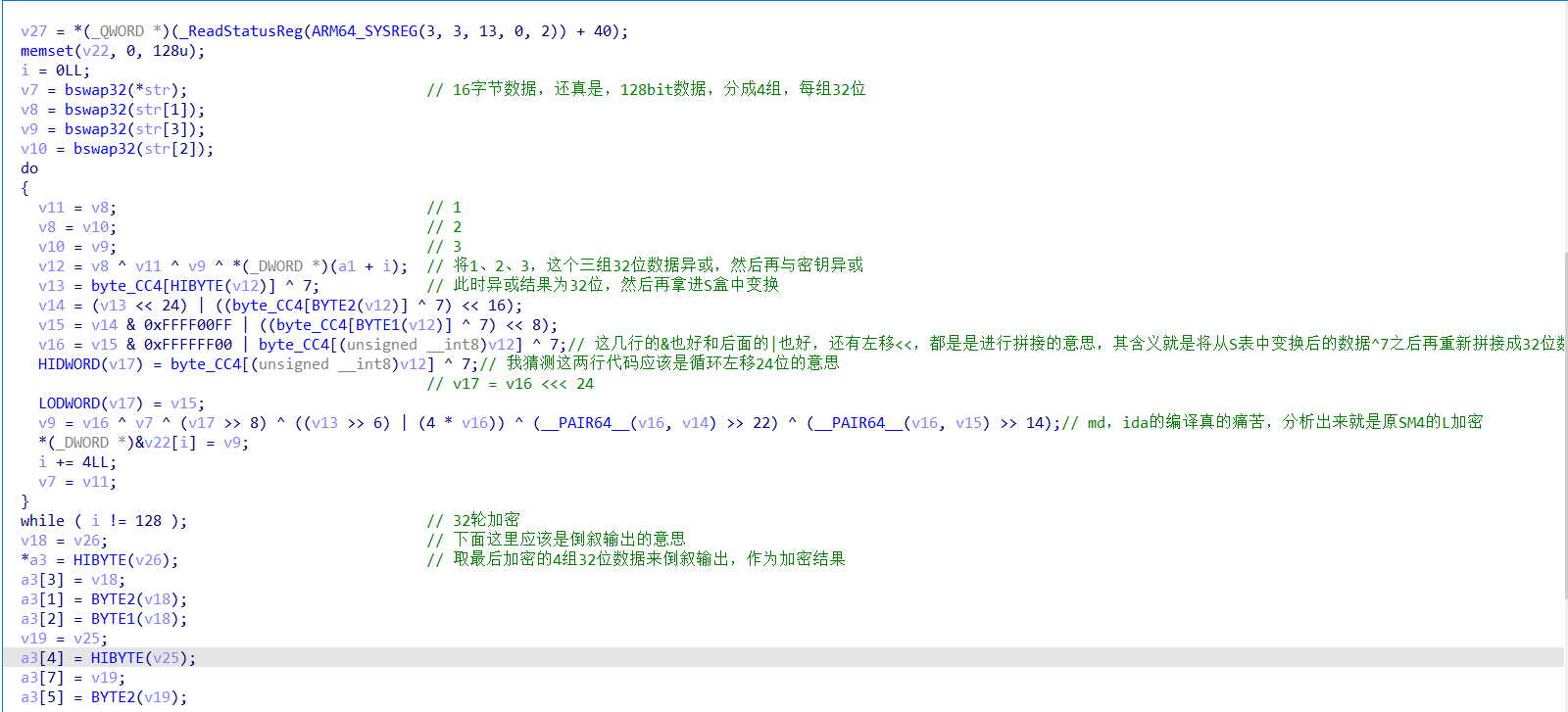
这里面的代码我详细说明中间的循环部分:
do
{
v11 = v8; // 1
v8 = v10; // 2
v10 = v9; // 3
v12 = v8 ^ v11 ^ v9 ^ *(_DWORD *)(a1 + i); // 将1、2、3,这个三组32位数据异或,然后再与密钥异或
v13 = byte_CC4[HIBYTE(v12)] ^ 7; // 此时异或结果为32位,然后再拿进S盒中变换
v14 = (v13 << 24) | ((byte_CC4[BYTE2(v12)] ^ 7) << 16);
v15 = v14 & 0xFFFF00FF | ((byte_CC4[BYTE1(v12)] ^ 7) << 8);
v16 = v15 & 0xFFFFFF00 | byte_CC4[(unsigned __int8)v12] ^ 7;// 这几行的&也好和后面的|也好,还有左移<<,都是是进行拼接的意思,其含义就是将从S表中变换后的数据^7之后再重新拼接成32位数据
HIDWORD(v17) = byte_CC4[(unsigned __int8)v12] ^ 7;// 猜测这两行代码应该是循环左移24位的意思
// v17 = v16 <<< 24
LODWORD(v17) = v15;
v9 = v16 ^ v7 ^ (v17 >> 8) ^ ((v13 >> 6) | (4 * v16)) ^ (__PAIR64__(v16, v14) >> 22) ^ (__PAIR64__(v16, v15) >> 14);// md,ida的编译真的痛苦,分析出来就是原SM4的L加密
*(_DWORD *)&v22[i] = v9;
i += 4LL;
v7 = v11;
}
while ( i != 128 ); // 32轮加密
讲解之前最好对SM4算法有一定了解,可以去看一下这篇帖子1。
- 首先来看一下这几行代码:
v11 = v8; // 1
v8 = v10; // 2
v10 = v9; // 3
v12 = v8 ^ v11 ^ v9 ^ *(_DWORD *)(a1 + i);
这里ida有点混乱,实际上应该如下:
int str[0] = input[0]; //这里都用4字节int型来装填数据,因为SM4要求输入必须是128bit
int str[1] = input[1]; //而SM4在加密时会分成4组4字节数据来进行加密操作
int str[2] = input[2];
int str[3] = input[3];
temp = str[1] ^ str[2] ^ str[3] ^ key[i]; //SM4每一加密轮的首组4字节数据只会在每一轮的最后参与运算,而每一加密的密钥都不相同。最后temp为32bit数据
- 再来看这几行代码:
v13 = byte_CC4[HIBYTE(v12)] ^ 7; // 此时异或结果为32位,然后再拿进S盒中变换
v14 = (v13 << 24) | ((byte_CC4[BYTE2(v12)] ^ 7) << 16);
v15 = v14 & 0xFFFF00FF | ((byte_CC4[BYTE1(v12)] ^ 7) << 8);
v16 = v15 & 0xFFFFFF00 | byte_CC4[(unsigned __int8)v12] ^ 7;// 这几行的&也好和后面的|也好,还有左移<<,都是是进行拼接的意思,其含义就是将从S表中变换后的数据^7之后再重新拼接成32位数据
这里ida也反编译得很乱,实际上应该如下:
temp[0] = S[temp[0]&0xF0][temp[0]&0x0F] ^ 7; //也就是将32bit的temp,再次分成4组8bit数据,然后将每组8bit中的高4位做为行,低4位作为列,然后拿这个当成坐标去S这个表中去寻值,最后将寻到的值再异或7之后重新赋给temp[0],而这里的异或也是本题对SM4算法的改动之一(异或完之后,会发现就是原SM4的S盒)
temp[1] = S[temp[1]&0xF0][temp[1]&0x0F] ^ 7;
temp[2] = S[temp[2]&0xF0][temp[2]&0x0F] ^ 7;
temp[3] = S[temp[3]&0xF0][temp[3]&0x0F] ^ 7;
你问我为什么是怎么还原这里的逻辑的,拿草稿自己算一遍:由于v13在ida中是一个int8类型的数据,v14、v15、v16都是int类型,同时HIBYTE(v12)的意思是取最高8位的数据,BYTE2(v12)是取次高8位数据,byte_CC4[BYTE1(v12)以此类推是取次低8位数据,(unsigned __int8)v12是取最低8位数据,其次当v13左移24位时,不就是将它的8位数据移到32位(因为v14是int类型)的最高8位嘛,然后将该数据或运算| 一个左移16位的数据,就是将该8位数据与前8位数据拼接在一起组成32位数据的前16位……所以拿草稿自己模拟一遍,逻辑就很清晰了。后两行代码逻辑和前面一样都是拼接逻辑,然后组成一个新32位数据。
- 接着再看这几行代码:
HIDWORD(v17) = byte_CC4[(unsigned __int8)v12] ^ 7;// 我猜测这两行代码应该是循环左移24位的意思, v17 = v16 <<< 24
LODWORD(v17) = v15;
v9 = v16 ^ v7 ^ (v17 >> 8) ^ ((v13 >> 6) | (4 * v16)) ^ (__PAIR64__(v16, v14) >> 22) ^ (__PAIR64__(v16, v15) >> 14);// md,ida的编译真的痛苦,分析出来就是原SM4的L加密(这里的代码看汇编会更容易分析)
这里的代码相当鬼,ida的反编译有时候就是这么痛苦,明明一个简单的代码都能被编译成这个样子……
这里的逻辑大致梳理一下:v17是一个int64类型的数据,对比我上面写的temp,大概就是将原32位数据temp[0]、temp[1]、temp[2]、temp[3],调换原最低8位数据位置到现高32位的最低8位,即变成如下:
0、0、0、temp[3]、temp[0]、temp[1]、temp[2]、0,这样的64位数据,其中0代表整个字节都为0,然后再将该数据也就是v17右移8位,也就是变成如下:
0、0、0、0、temp[3]、temp[0]、temp[1]、temp[2],这样的64位数据,说白了就是将原32位temp循环左移24位,即:temp<<<24。
同样的后面的((v13 >> 6) | (4 * v16)),就是将temp循环左移2位,即:temp<<<2。
而(__PAIR64__(v16, v14) >> 22),就是将temp循环左移10位,即:temp<<<10,这里要说明一下(__PAIR64__(v16, v14) >> 22)是什么意思,这里是ida的特殊写法,它的等效代码可以写做如下:
uint64_t combined = ((uint64_t)v16 << 32) | v14;
uint64_t result = combined >> 22;
这里还是要拿草稿计算一下,由于这里被转成了64位数据,所以最后还需要将上述过程形成的64位数据重新转成32位,也就是说高位数据多出的部分要丢弃。
最后的(__PAIR64__(v16, v15) >> 14),就是将temp循环左移18位,即:temp<<<18。
所以第3部分的代码实际如下:
_temp_ = str[0] ^ temp ^ (temp<<<2) ^ (temp<<<10) ^ (temp<<<18) ^ (temp<<<24);
- 最后再来看这部分的代码:
*(_DWORD *)&v22[i] = v9;
i += 4LL;
v7 = v11;
这部分的代码包括了循环递增以及数据的偏移变化,上面也说了我们的输入是128bit,而每一轮加密结束都会新增一个32位数据到原数据的末尾,为了确保每一轮加密都是128bit,所以每一轮加密后,待加密数据都会向后偏移32bit。
举个例子:
第一轮待加密数据如下:(每个str[]都是32bit数据)
str[0] str[1] str[2] str[3]
第一轮加密结束后的数据如下:
str[0] str[1] str[2] str[3] Str[4],其中str[4]是第一轮加密结果
第二轮待加密数据如下:(每轮加密结束后向后移动32bit)
str[1] str[2] str[3] Str[4]
以此类推……执行32轮加密,取最后4个32bit数据,再倒序,作为加密结果。
解密
最后需要比对的正确密文在ida解析后也不难找到,正确的密文内容如下:
A27C84EDE57F4EDE9D977F6C69339F2752E6067920A2C3B7A6BE2B4A6231650C51160EF0A39807DD8F40CF021D482310
剩下的就只有解密了,最后附上一个SM4解密脚本:
S_BOX = [0xd1, 0x97, 0xee, 0xf9, 0xcb, 0xe6, 0x3a, 0xb0, 0x11, 0xb1, 0x13, 0xc5, 0x2f, 0xfc, 0x2b, 0x2, 0x2c, 0x60, 0x9d, 0x71, 0x2d, 0xb9, 0x3, 0xc4, 0xad, 0x43, 0x14, 0x21, 0x4e, 0x81, 0x1, 0x9e, 0x9b, 0x45, 0x57, 0xf3, 0x96, 0xe8, 0x9f, 0x7d, 0x34, 0x53, 0xc, 0x44, 0xea, 0xc8, 0xab, 0x65, 0xe3, 0xb4, 0x1b, 0xae, 0xce, 0xf, 0xef, 0x92, 0x87, 0xd8, 0x93, 0xfd, 0x72, 0x88, 0x38, 0xa1, 0x40, 0x0, 0xa0, 0xfb, 0xf4, 0x74, 0x10, 0xbd, 0x84, 0x5e, 0x3b, 0x1e, 0xe1, 0x82, 0x48, 0xaf, 0x6f, 0x6c, 0x86, 0xb5, 0x76, 0x63, 0xdd, 0x8c, 0xff, 0xec, 0x8, 0x4c, 0x77, 0x51, 0x9a, 0x32, 0x19, 0x23, 0x9, 0x59, 0x64, 0x5f, 0xd6, 0xa5, 0x22, 0x25, 0x7b, 0x3c, 0x6, 0x26, 0x7f, 0x80, 0xd3, 0x7, 0x41, 0x50, 0x98, 0xd4, 0x20, 0x55, 0x4b, 0x31, 0x5, 0xe0, 0xa7, 0xc3, 0xcf, 0x99, 0xed, 0xb8, 0x8d, 0xd5, 0x47, 0xc0, 0x3f, 0xb2, 0xa4, 0xf0, 0xf5, 0xc9, 0xfe, 0x66, 0x12, 0xa6, 0xe7, 0xa9, 0x5a, 0xa3, 0x9c, 0x33, 0x1d, 0x52, 0xaa, 0x94, 0x35, 0x37, 0xf2, 0x8b, 0xb6, 0xe4, 0x1a, 0xf1, 0xe5, 0x29, 0x85, 0x61, 0xcd, 0x67, 0xc7, 0x2e, 0x24, 0xac, 0xa, 0x54, 0x49, 0x68, 0xd2, 0xdc, 0x30, 0x42, 0xd9, 0xfa, 0x89, 0x28, 0x4, 0xf8, 0x6d, 0x75, 0x6a, 0x6b, 0x5c, 0x56, 0x8a, 0x1c, 0xa8, 0x95, 0xbc, 0xda, 0xbb, 0x78, 0x16, 0xde, 0x5b, 0x46, 0x18, 0x17, 0x5d, 0xdf, 0xd, 0xc6, 0x36, 0x8f, 0xa2, 0xca, 0x7c, 0xba, 0x2a, 0x73, 0xd7, 0x15, 0xbf, 0xe2, 0xb3, 0xb7, 0x8e, 0x6e, 0x90, 0x4d, 0xb, 0x91, 0x70, 0x79, 0x62, 0xbe, 0xf6, 0xe, 0xc2, 0x69, 0xc1, 0x83, 0x1f, 0xf7, 0x7a, 0xeb, 0x3d, 0xdb, 0x4a, 0x27, 0x7e, 0xe9, 0x58, 0x39, 0xd0, 0xcc, 0x3e, 0x4f]
# 换为S盒
for i in range(len(S_BOX)):
S_BOX[i] ^= 7
FK = [0xa3b1bac6, 0x56aa3350, 0x677d9197, 0xb27022dc]
CK = [
0x00070e15, 0x1c232a31, 0x383f464d, 0x545b6269,
0x70777e85, 0x8c939aa1, 0xa8afb6bd, 0xc4cbd2d9,
0xe0e7eef5, 0xfc030a11, 0x181f262d, 0x343b4249,
0x50575e65, 0x6c737a81, 0x888f969d, 0xa4abb2b9,
0xc0c7ced5, 0xdce3eaf1, 0xf8ff060d, 0x141b2229,
0x30373e45, 0x4c535a61, 0x686f767d, 0x848b9299,
0xa0a7aeb5, 0xbcc3cad1, 0xd8dfe6ed, 0xf4fb0209,
0x10171e25, 0x2c333a41, 0x484f565d, 0x646b7279
]
def wd_to_byte(wd, bys):
bys.extend([(wd >> i) & 0xff for i in range(24, -1, -8)])
def bys_to_wd(bys):
ret = 0
for i in range(4):
bits = 24 - i * 8
ret |= (bys[i] << bits)
return ret
def s_box(wd):
"""
进行非线性变换,查S盒
:param wd: 输入一个32bits字
:return: 返回一个32bits字 ->int
"""
ret = []
for i in range(0, 4):
byte = (wd >> (24 - i * 8)) & 0xff
row = byte >> 4
col = byte & 0x0f
index = (row * 16 + col)
ret.append(S_BOX[index])
return bys_to_wd(ret)
def rotate_left(wd, bit):
"""
:param wd: 待移位的字
:param bit: 循环左移位数
:return:
"""
return (wd << bit & 0xffffffff) | (wd >> (32 - bit))
def Linear_transformation(wd):
"""
进行线性变换L
:param wd: 32bits输入
"""
return wd ^ rotate_left(wd, 2) ^ rotate_left(wd, 10) ^ rotate_left(wd, 18) ^ rotate_left(wd, 24)
def Tx(k1, k2, k3, ck):
"""
密钥扩展算法的合成变换
"""
xor = k1 ^ k2 ^ k3 ^ ck
t = s_box(k1 ^ k2 ^ k3 ^ ck)
return t ^ rotate_left(t, 13) ^ rotate_left(t, 23)
def T(x1, x2, x3, rk):
"""
加密算法轮函数的合成变换
"""
t = x1 ^ x2 ^ x3 ^ rk
t = s_box(t)
return t ^ rotate_left(t, 2) ^ rotate_left(t, 10) ^ rotate_left(t, 18) ^ rotate_left(t, 24)
def key_extend(main_key):
MK = [(main_key >> (128 - (i + 1) * 32)) & 0xffffffff for i in range(4)]
# 将128bits分为4个字
keys = [FK[i] ^ MK[i] for i in range(4)]
# 生成K0~K3
RK = []
for i in range(32):
t = Tx(keys[i + 1], keys[i + 2], keys[i + 3], CK[i])
k = keys[i] ^ t
keys.append(k)
RK.append(k)
return RK
def R(x0, x1, x2, x3):
# 使用位运算符将数值限制在32位范围内
x0 &= 0xffffffff
x1 &= 0xffffffff
x2 &= 0xffffffff
x3 &= 0xffffffff
s = f"{x3:08x}{x2:08x}{x1:08x}{x0:08x}"
return s
def encode(plaintext, rk):
X = [plaintext >> (128 - (i + 1) * 32) & 0xffffffff for i in range(4)]
for i in range(32):
t = T(X[1], X[2], X[3], rk[i])
c = (t ^ X[0])
X = X[1:] + [c]
ciphertext = R(X[0], X[1], X[2], X[3])
# 进行反序处理
return ciphertext
def decode(ciphertext, rk):
ciphertext = int(ciphertext, 16)
X = [ciphertext >> (128 - (i + 1) * 32) & 0xffffffff for i in range(4)]
for i in range(32):
t = T(X[1], X[2], X[3], rk[31 - i])
c = (t ^ X[0])
X = X[1:] + [c]
m = R(X[0], X[1], X[2], X[3])
return m
def output(s, name):
out = ""
for i in range(0, len(s), 2):
out += s[i:i + 2] + " "
print(f"{name}:", end="")
print(out.strip())
def output2(s, name):
out = ""
for i in range(0, len(s), 2):
out += chr(eval('0x'+s[i:i + 2]))
print(f"{name}", end="")
print(out, end='')
# print(out)
if __name__ == '__main__':
key = '4131313232333537343638393930305A'
main_key = eval('0x'+key)
rk = key_extend(main_key)
print("解密:")
cipher = 'A27C84EDE57F4EDE9D977F6C69339F2752E6067920A2C3B7A6BE2B4A6231650C51160EF0A39807DD8F40CF021D482310'
for i in range(len(cipher) // 32):
ciphertext = cipher[32*i: 32*(i+1)]
# print(ciphertext)
m = decode(ciphertext, rk)
output2(m, "")
出来的结果为:flag{eb83c643-d0ee-4db6-bc35-96e11283bd21}
REVERSE02
这道题比较简单,根据提示,这道题应该有4层加密。
拖入ida中查看,发现对字符串格式进行了校验,如下图:

同时根据赛题提示与伪代码的分析,发现有4层简单加密,如下图:
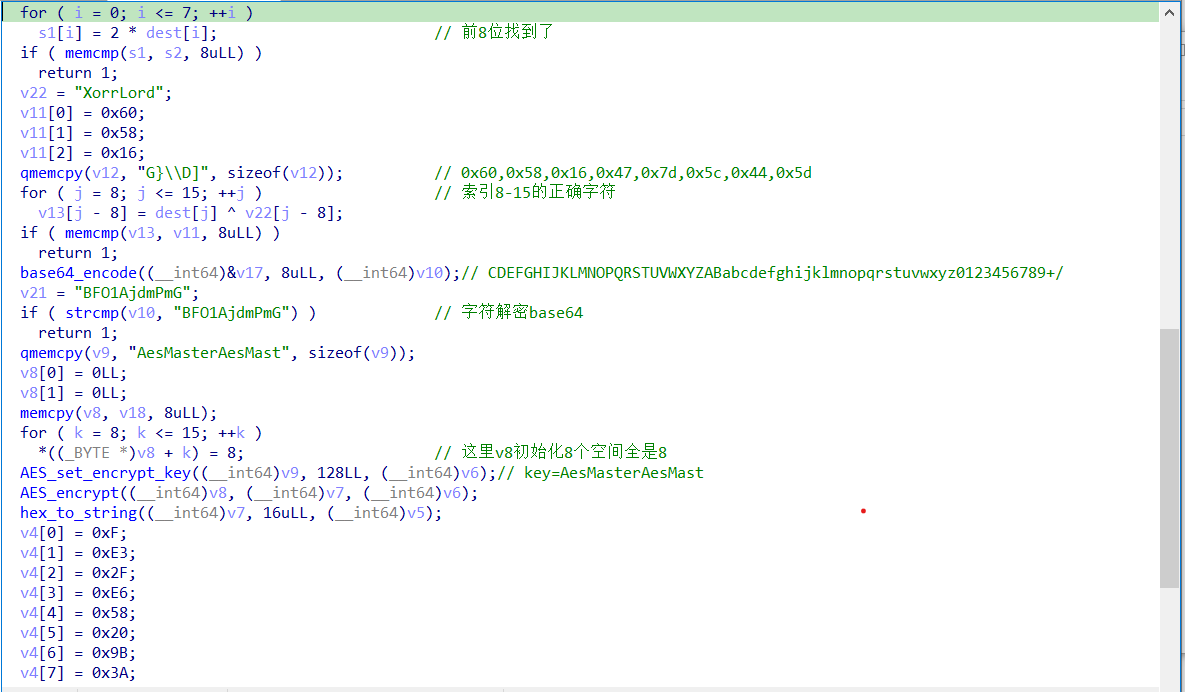
加密分析
第一层加密:
将字符串的前8位左移1位加密。
第二层加密:
就是将字符串的第9位到第16位与XorrLord进行异或,然后与下面这8字节数据进行校验:
0x60,0x58,0x16,0x47,0x7d,0x5c,0x44,0x5d
第三层加密:
将字符串的第17位到第24位进行换表base64加密,最后与BFO1AjdmPmG进行比较,映射表如下:
CDEFGHIJKLMNOPQRSTUVWXYZABabcdefghijklmnopqrstuvwxyz0123456789+/
第四层加密:
将字符串最后8位数据进行AES加密,密钥为AesMasterAesMast,最后与下面16字节数据进行比较:
0xF, 0xE3, 0x2F, 0xE6, 0x58, 0x20, 0x9B, 0x3A, 0xD6, 0xE4, 0x18, 0x3F, 0xA7, 0x78,0xA5, 0x82
最后分别写出解密脚本,我这里从最后一层开始解密。(其实可以一个脚本全部写完,主要是懒得写了🥴)
解密
第四层解密:
from Crypto.Cipher import AES
# 加密的 16 字节数据
encrypted_data = bytes([
0xF, 0xE3, 0x2F, 0xE6,
0x58, 0x20, 0x9B, 0x3A,
0xD6, 0xE4, 0x18, 0x3F,
0xA7, 0x78, 0xA5, 0x82
])
# 原密钥(16 字节)
key = b"AesMasterAesMast"
# 使用 AES 解密(ECB 模式)
cipher = AES.new(key, AES.MODE_ECB)
# 解密数据
decrypted_data = cipher.decrypt(encrypted_data)
# 将解密后的数据按字节输出为十六进制
hex_output = " ".join(f"{byte:02x}" for byte in decrypted_data)
print("解密后的十六进制数据:", hex_output)
得到61 64 32 65 34 35 36 31
(其实上面的结果后面还会跟上8个8,但是根据源码分析,只有前8字节才有用)
第三层解密:
import base64
# 示例的 base64 数据(替换为你的数据)
encoded_data = "BFO1AjdmPmG"
# 自定义的 base64 字符映射表
custom_base64_table = "CDEFGHIJKLMNOPQRSTUVWXYZABabcdefghijklmnopqrstuvwxyz0123456789+/" # 自定义映射表
standard_base64_table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# 构建自定义 base64 解码表
translation_table = str.maketrans(custom_base64_table, standard_base64_table)
translated_data = encoded_data.translate(translation_table)
# 检查并修复填充
missing_padding = len(translated_data) % 4
if missing_padding:
translated_data += "=" * (4 - missing_padding) # 添加必要的填充
# 使用标准 base64 解码
try:
decoded_data = base64.b64decode(translated_data)
# 将解码后的数据按字节转换为十六进制并逐个输出
hex_output = " ".join(f"{byte:02x}" for byte in decoded_data)
print("解码后的十六进制数据:", hex_output)
except base64.binascii.Error as e:
print("解码错误:", e)
得到64 33 35 62 37 66 36 61
第二与第一层解密:
#include <stdio.h>
int main()
{
unsigned char str1[] = {0x6A,0x0C4,0x0CC,0x62,0x0C2,0x6E,0x0CA,0x0CA};
char temp1[9];
for(int i=0;i<8;i++)
{
temp1[i] = str1[i] >> 1;
printf("%x ",temp1[i]);
}
printf("\n");
char str2[] = {0x60,0x58,0x16,0x47,0x7d,0x5c,0x44,0x5d};
char* xorr = "XorrLord";
char temp2[9];
for(int i=0;i<8;i++)
{
temp2[i] = str2[i] ^ xorr[i];
printf("%x ",temp2[i]);
}
printf("\n");
unsigned char test[] = {0x35 ,0x62 ,0x66 ,0x31 ,0x61 ,0x37 ,0x65 ,0x65};
unsigned char temp[9];
for(int i=0;i<8;i++)
{
temp[i] = test[i] << 1;
printf("%x ",temp[i]);
}
return 0;
}
然后依次连接以上四部分数据然后转成ascii码获取flag
最后将数据汇总转成flag即可:wdbflag{5bf1a7ee87d51369d35b7f6aad2e4561}